Tips and tricks from a developer’s experience that you can apply to make your own Linx solution cleaner and easier to maintain and understand.
The amount of code in a complex application is enormous. Thousands of lines of code, hundreds of methods and classes means having meaningful and easy to interpret code is obligatory in big applications if you don’t want to get lost in the jungle. Even when applied to the emerging market of low-code tools, clean code rules still apply in one way or another.
With low-code development tools, the abstraction layer removes the need to learn coding, design patterns, and their associated best practices and pitfalls. But you can easily duplicate actions, create cumbersome processes and use ambiguous naming. Suddenly you notice the number of bugs are increasing while the amount of new functionality is decreasing.
As an experienced C# developer, applying the same coding practices is almost instinctual, even when working in a low-code application such as Linx. If you are working in a large Linx solution and components don’t have meaningful names or follow natural programming rules and best practices, life can get just a tad frustrating.
Let’s look at some common pitfalls and the best practices we can apply to fix them.
The Name Game
Naming – the bane of a developer’s existence. As a developer, you spend more time reading code than actually writing code, so if methods, variables, etc. are poorly named, it can be even more time-consuming to try and understand what is happening.
By applying good naming practices, it will become intuitive for you or for the next person that has to work on the solution, to identify and understand what is going on. You don’t always get it right on the first go, but you can refine and improve as you go along. Naming can be difficult, but it is well worth the effort, in the long run, to keep your solution clean and readable.
Here are 3 practices that you can implement in your solution:
1. Meaningful Names
Give names that reveal intent. Questions that you can ask yourself are “What is it doing?” “What is its responsibility?” “What is its purpose?” The name should clearly tell you what something is doing or what something is for without ambiguity.
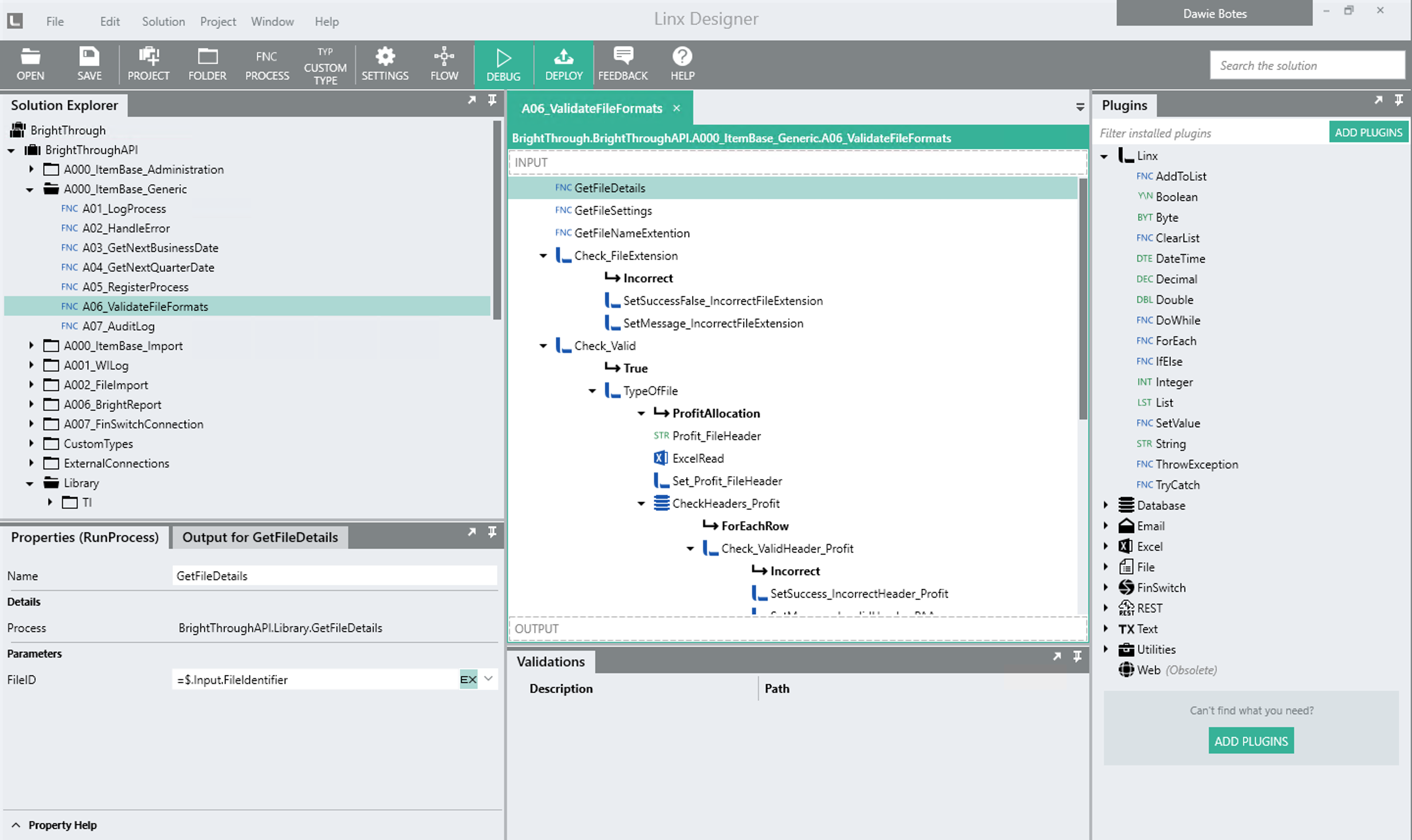
For example, consider the following process:
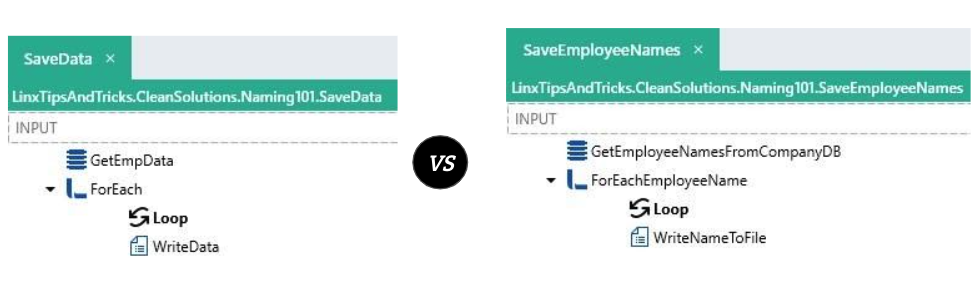
2. Pronouneceable Names
It’s easier for humans to understand when we can read names like a standard word or sentence without making assumptions about what the name could be. This will also make searching easier.
For example, consider the following Custom Type called EmpRcrd vs the Custom Type called Employee
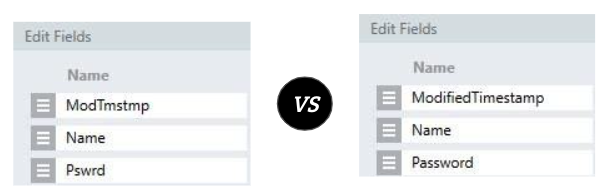
These 2 practices can be extended to your solution settings too. For example:

3. Pick one word for the same concept
When working in a large solution, you will likely have many instances where you are doing the same kind of thing, such as getting values or deleting something. You might choose words like get and delete, but someone else might use retrieve and remove. This will cause inconsistencies in the solution and make searching a little more complicated. Pick one word for the same concept and stick with it throughout the solution.
Process Pains
As a developer, there are times when you come across methods in code that are way too long and do way too much, which results in the functionality being difficult to follow and understand. The same can be said for big processes in Linx. For clean processes in Linx, there are 2 leading coding practices that you can implement in your solution:
- Break a big process down into smaller, logical processes
A process is like a function in programming, and each function should be responsible for one thing. This way, the logic is contained and any further changes are isolated to each smaller process, making it easier to identify issues and to maintain.
- DRY (Don’t Repeat Yourself)
In programming, there is a principle called DRY – If you see that you are implementing the same piece of functionality in multiple places, it is a good idea to extract it into a separate process. By doing this, the logic is contained and future changes and fixes are done in one place. This will eliminate the risk of not updating and fixing all occurrences in your solution.
With these 2 practices, you can make use of process input and output parameters to pass values along where necessary. Consider the following example:

This example is not to scale, but we can get an idea of how a process that has many functions can become difficult to follow and maintain. Notice the duplicated functionality of logging errors to a text file and then uploading the file to Google Drive.
Vs..
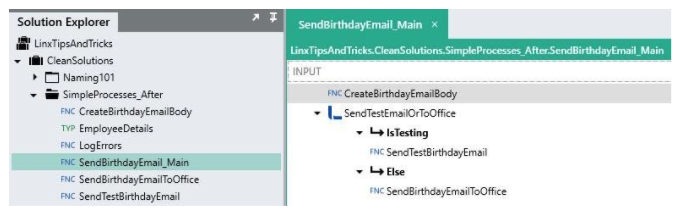
This looks a lot better. Here we can see how each part of the functionality has been extracted into a separate process, keeping the logic isolated and easier to maintain and our primary process simple. The duplicated functionality for logging errors has also been extracted into a separate process.
Here’s a look at each separate process:
CreateEmailBody:
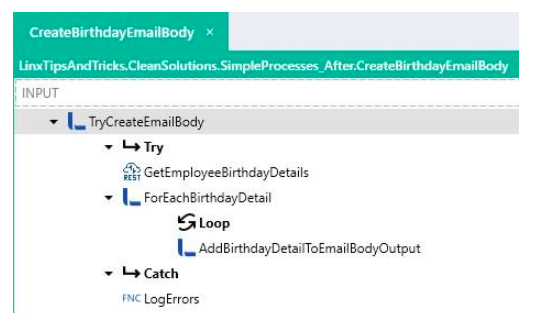
The email body is an output parameter on the process, which can then be passed along to other processes/functions that require it.
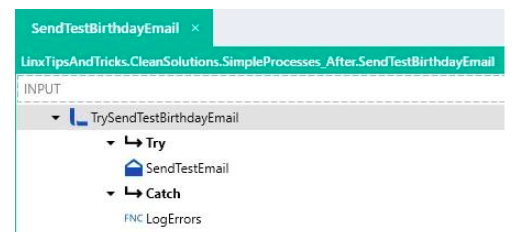
SendTestBirthdayEmail:
SendBirthdayEmailToOffice:
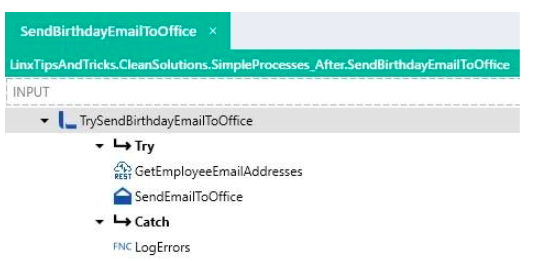
For these 2 processes that send the email, the email body created previously can now be passed in via an input parameter on these processes.
LogErrors:
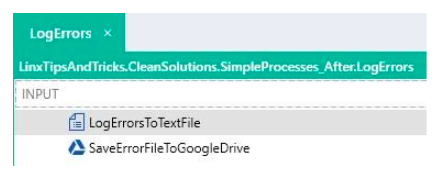
The duplicated functionality of logging errors has been extracted into its process. This way, if any changes or fixes need to be made, it is all done in one place. For example, if you wish to swap uploading the text file from Google Drive to Azure or Amazon storage, it can be done in one process and not 100 other places. Any data required can be passed in via input parameters on the process, such as content for the text file, which could be the exception message from the try-catch. By implementing these practices, your processes will become easier to understand and to maintain in the future, not just for yourself, but also the next person that might work on the solution.
Wrapping Up
Code readability is a universal subject in the world of computer programming. It’s one of the first things we learn as developers. Writing and reading code may look “easy” if you know what you are doing, but you are probably not the only one working on the solution. If you work in a team, it is a good idea to define best practices and guidelines so that it is easier for the other team members to read, edit, review and maintain the solution. Following best practices will also help you be a better programmer overall. And don’t forget Rule #1 – consistency, simplicity, and readability
Happy cleaning!