We recently discovered open-source workflow engine Camunda after one of our customers mentioned using it with our low-code tool. After looking through Camunda’s documentation, I realized it could be a perfect partner for Linx.
Workflow (or Business Process Management) software generally covers three areas:
- 1. Workflow engine. The engine keeps state and decides what must happen next.
- 2. User task management. The user interface and logic that governs task allocation to users and how they interact with those tasks.
- 3. Automated task execution. The mechanism to interact with other technologies.
These may be connectors to APIs or hooks into one or more programming languages. Camunda covers all these areas and has a comprehensive REST API. You can run it as a standalone service and hook up a custom user task interface and automated task execution to the API.
Automated tasks are usually programmed in a language the workflow engine supports. In Camunda’s case, it’s Java or, by using the REST API, the language of your choice. Another way to develop automated tasks is to use a low-code tool — I thought the two would work well together.
Try it! The project is available for you to sample
The project on GitHub
Linx documentation
Camunda documentation
Hypotheses
In theory, using a workflow engine to orchestrate business processes built with a low-code tool should give us the best of both worlds. We design the workflow with a BPMN modeling tool and create the task automation using low-code. When doing the modeling, we concentrate on the business problem, and when implementing the automated tasks, we focus on the technical aspects but without having to code.
The separation of the orchestration (workflow engine) and task automation (low-code) has some other advantages:
- Maintenance. We can make changes on one without impacting the other one.
- Flexibility. We can mix execution technologies e.g. use low-code where we can and code where we have to. Or have multiple, even different, workflow engines. Whatever works for the scenario.
- Performance. We can scale the area that requires it e.g. if the workflow engine struggles, we scale that, and if any of the execution tasks need resources we scale that.
- Testing. We can test process logic and task execution separately.
And some downsides:
- Headaches. More than one technology to maintain.
- Complexity. It might not always be obvious how the different pieces fit together, making it more challenging to maintain.
Test
Lots of our customers still use files as part of their system integration flows. Files from System A are used to update System B. There are usually tens to hundreds of formats with different rules to apply. A common way to do this is to import the file into a staging database, enrich the data, validate the data, and then update the target.
So to test the idea of using Linx with Camunda, I built a generic file import process. We add new file imports by adding task automation in Linx. The workflow itself stays the same.
The generic file import process looks like this:
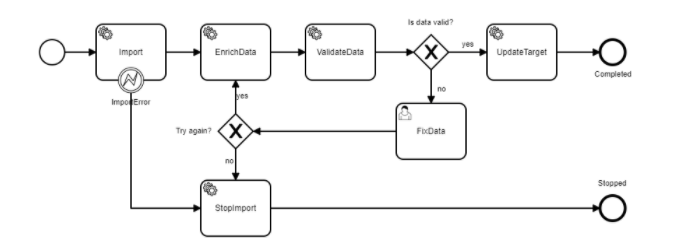
All the Service Tasks (those with the gears) are also External Tasks. They are executed outside of Camunda, in this case by Linx. My initial architecture had Camunda calling a Microservice hosted by Linx to execute the tasks.
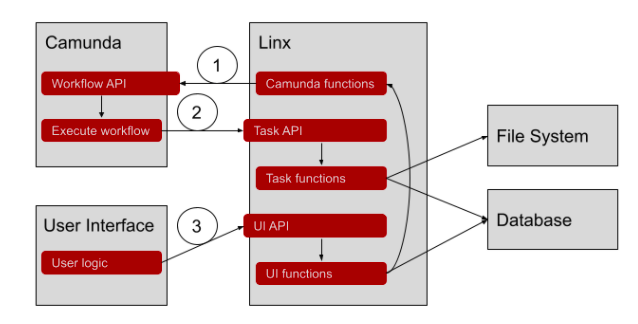
- Linx calls the Camunda API to start a new process instance.
- Camunda call the Linx Task API when it processes an External Task. It waits when it reaches a User Task.
- User Interface calls the Linx UI API when the user completes a User Task. Linx notifies Camunda that the task is complete.
But after figuring out that I would have to write code and do some configuration of my Camunda instance to be able to call external APIs, I decided to try a different tact and ended up with this:
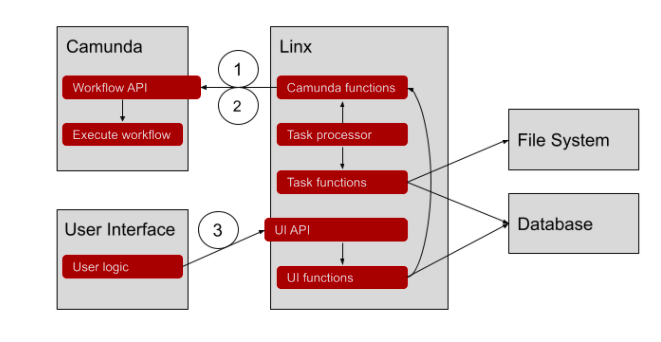
- Linx calls the Camunda API to start a new process instance.
- Linx polls Camunda for External Tasks, executes them, and notifies Camunda that the task is complete.
- User Interface calls the Linx UI API when the user completes a User Task. Linx notifies Camunda that the task is complete.
Linx polls Camunda for work and executes it instead of Camunda calling into Linx. The process of building it was easier than expected.
- Design the workflow with Camunda Modeler.
- Create a function in Linx for each Service Task in Camunda. These functions should be idempotent as they might be called more than once for the same workflow instance if something goes wrong between Camunda and Linx.
- Create a Timer Service in Linx to poll Camunda for tasks.
- Add a function in Linx to match the Task Id with its related Linx function.
Result
I quite like how this turned out. Combining a proper workflow engine with a developer-friendly low-code tool gives us the best of both worlds. It’s overkill for simple processes, but the added complexity should be worth it when they get elaborate.
Further reading: Choosing the right API development tools